-
C언어에서의 다차원 데이터 메모리 할당 방법Programming/TIL 2024. 10. 16. 01:02
C언어에서 다차원 데이터, 혹은 다차원 배열의 메모리 동적 할당 방법을 다룹니다.
터를 이용한 기초적인 방법부터, 일차원으로 메모리를 할당하는 선형 방식, 선형 데이터에 이차원 배열의 인터페이스([][])를 사용하는 방법, VLA(Variable Length Array)를 사용하는 방법 등 각 방식의 장단점을 이차원 데이터를 할당하는 예시 코드와 함께 설명합니다.개요
프로그래밍을 하다 보면 2차원 이상의 데이터 구조를 다뤄야 할 때가 있습니다.
게임의 맵 정보나 픽셀로 이루어진 이미지 데이터, 행렬과 테이블 데이터 등이 대표적입니다.이런 다차원 데이터는 컴파일 시점에 크기를 알 수 없는 경우가 많습니다.
게임 맵 크기가 실행 중에 결정되거나, 처리할 이미지의 해상도를 사전에 알지 못하는 경우가 대표적이죠.
이럴 때 프로그램은 실행 중에 필요한 만큼 메모리를 할당해야 합니다. 동적 할당이 필요한 거죠.C언어에서 이런 다차원 데이터를 위한 메모리를 어떻게 할당하면 좋을지, 어떤 방식이 효율적인지 알아보겠습니다.
글은 C언어와 메모리 구조에 대한 기초적인 지식을 전제로 합니다.
배열과 포인터의 차이를 알고 읽으면 더욱 좋습니다.
C언어의 여러 구현 전략을 다루지만, 다른 언어를 주로 사용하더라도 흥미롭게 읽을 수 있도록 (나름) 노력했습니다.상황 설정
설명을 위한 상황 설정을 먼저 하겠습니다.
간단한 지뢰 찾기 게임을 만든다고 가정해 봅시다.
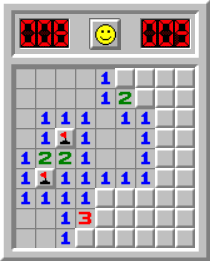
위 이미지는 지뢰 찾기 초급 난이도 화면입니다. 세로 9칸, 가로 9칸 게임판에 지뢰가 10개 매설되어 있습니다.
난이도가 올라갈수록 게임판 크기는 커지고, 지뢰 개수도 늘어납니다.커스텀 난이도도 있습니다. 사용자가 게임판 크기와 지뢰 수를 원하는 만큼 설정할 수 있죠.
플레이타임을 늘리기 위해 커스텀 난이도를 지원해 보겠습니다.먼저 세로 크기(
n_rows)와 가로 크기(n_cols)를 입력받고, 그에 맞는 게임판을 생성해야 합니다.
컴파일 시점에서 필요한 크기를 알 수 없기 때문에, 동적으로 메모리를 할당해 주어야 합니다.데이터는
int를 저장한다고 가정하겠습니다. 게임판 이름은board가 좋겠군요.코드를 작성해 봅시다. 어떻게 짜실 건가요?
가장 친숙한 방식: 행별 메모리 할당
이런 코드를 생각했나요?
저도 이렇게 메모리를 할당하고 있었습니다.
많은 인터넷 튜토리얼에 나오는 기본적인 방법입니다.
이중 포인터를 사용해서 한 줄씩 메모리를 할당해 주는 방식이죠.board가 가리키는 곳에 포인터가n_rows개 있고, 각 포인터는n_cols개의 데이터가 저장된 위치를 가리킵니다.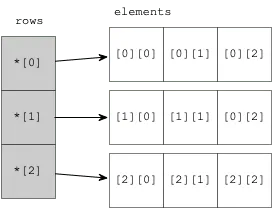
여기에는 몇 가지 문제가 있습니다.
문제1: 할당 횟수가 많아 번거롭다
코드에 에러 처리를 넣는다고 해 봅시다.
malloc()호출 시마다 할당 성공 여부를 확인하고, 실패시 할당한 메모리를 해제하도록 했습니다.코드는 메모리 할당을 총
n_rows + 1번 수행합니다. 체크해야 할 지점도n_rows + 1개입니다.
물론 간소화할 방법이야 많겠지만, 단순한 작업을 하는 코드가 복잡해지는 건 아주 싫죠.문제2: 많은 할당으로 인한 성능 저하
메모리 할당은 비용이 듭니다. 메모리상에서 적절한 공간을 찾아야 하고, 또 그 공간을 할당해야 하죠.
메모리를
n_rows + 1번 할당하며malloc함수의 사용료를n_rows + 1번 내는 셈입니다.데이터가 저장되는 방식도 비효율적입니다.
잠깐 그림을 다시 보죠.
board[0][0]에서board[0][2]까지의 데이터는 붙어서 저장이 됩니다. 같이 할당되었으니까요.한편
board[0][2]와board[1][0]는 붙어서 저장되지 않습니다.board[0]과board[1]은 따로(별도malloc호출로) 할당되었기 때문입니다.즉, 모든 row가 따로따로 흩어져 저장됩니다.
이는 메모리 단편화(Memory Fragmentation)를 야기합니다.

위 그림처럼, 메모리에 남는 공간이 있어도, 크기가 작아서 사용할 수 없게 되는 현상이죠.
실행 속도에도 부정적인 영향을 미칠 수 있습니다.
CPU는 메모리에서 주소 하나만 가져오지 않습니다. 주변 데이터도 같이 가져옵니다.
다음에 쓸 가능성이 높은 데이터를 미리 가져와 놓는 거죠. 이를 캐시 라인(Cache Line)이라고 합니다.
캐시에 올라간 데이터는 메모리에 위 데이터보다 훨씬 빠른 접근이 가능합니다.즉, 같이 쓰는 데이터는 인접한 공간에 저장할수록 처리 속도가 빨라질 수 있습니다.
지뢰 찾기 게임판의 크기
n_rows * n_cols는 한번 정해지면 더는 바뀌지 않습니다.
즉n_rows * n_cols크기의 메모리를 한꺼번에 할당하는 게 가장 좋겠죠.malloc호출에 따른 오버헤드도 줄이고, 데이터도 꾹꾹 뭉쳐 저장가능합니다.선형으로 다차원 데이터 할당하기
선형으로 저장하고 접근한다는 말의 의미
방법을 소개하기 전, 한가지 퀴즈를 내겠습니다.
변수가 두 개 있습니다.
board_a는 2차원 배열이고,board_d는 동적으로 할당된 2중 포인터입니다.같은 위치에서 데이터를 가져오겠습니다.
[1][2]에 있는 데이터요.val_a와val_d를 가져올 때, 컴퓨터는 같은 작업을 수행할까요? 아니면 다른 작업을 할까요?정답은 "다른 작업을 한다"입니다.
이는 배열과 포인터가 다르기 때문인데요.
배열은 컴퓨터가 크기를 알고 있습니다.
board_a는 3x5 크기 배열이라는 정보를 알고 있죠.board_a[i][j]를 가져올 때 컴퓨터는i * N_COLS + j만큼 메모리를 건너뛰어서 값을 가져옵니다.반면 포인터는 컴퓨터가 크기를 모릅니다. 그저
board_d는int **타입이라는 정보만 알 뿐이죠.board_d[i][j]를 가져올 때 컴퓨터는i번째 값을 찾은 뒤, 그 값이 가리키는 곳에서j번째 값을 가져옵니다.C언어에서 2차원 배열은 모든 데이터를 연속적으로 저장합니다.
이를N_COLS크기를 알고 있는 1차원 배열이라고 해석해 볼 수도 있습니다. 아래 코드처렴요.2차원 배열과 같은 원리로, 2차원 데이터를 1차원으로 저장하고 접근할 수 있습니다.
다차원 데이터 선형 할당
방법은 간단합니다.
n_rows * n_cols만큼 메모리를 한 번에 할당합니다.이차원 배열에서
board[i][j]에 접근하면, 컴파일러가i * N_COLS + j로 인덱스 계산을 해주었었죠.
이제는 우리가 직접 인덱스를 계산해서 값을 가져오면 됩니다.3차원도 마찬가지입니다.
곱해야 할 값이 많아져 조금 복잡해 보일 수 있습니다.
간단하게 하기 위해 차원별 데이터에 접근하기 위한 계수, stride를 따로 저장해 줍시다.메모리 할당 횟수는 단 한 번이고, 데이터도 인접하게 저장되어 있습니다.
한 가지 문제가 있다면 접근할 때마다 인덱스 계산이 필요하다는 점입니다.
메모리 할당보다는 데이터 접근을 할 일이 훨씬 많을 테니, 어찌 보면 귀찮음이 더 늘어난 셈이죠.물론 매크로나 함수를 따로 두면 편하게 접근이 가능하겠지만, 친숙하고 익숙한
board[i][j]와 같은 인터페이스를 사용할 수 없다는 점이 아쉽습니다.선형으로 데이터를 할당하면서도, 이차원 배열과 같은 인터페이스를 사용할 수는 없을까요?
이차원 배열의 인터페이스를 사용하는 방법
선형 데이터에 포인터 연결해 주기
먼저 방금처럼 선형으로 데이터를 할당합니다.
그다음 각 행 시작 주소를 가르키는 포인터를 두어 연결해 주는 방식입니다.
아래 그림처럼, 선형으로 저장된 데이터에 포인터를 따로 연결해 줌으로써
board[i][j]와 같은 이차원 배열 인터페이스를 사용할 수 있습니다.
단, 이전 방법과 비교하면 메모리 할당이 한 번 더 필요합니다. 포인터를 저장하기 위한 추가 메모리가 필요하니까요.
차원이 늘어날수록 연결할 포인터도 많이 늘어나고, 계산도 복잡해진다는 단점 역시 존재합니다.그래도 가장 처음 방법과 비교하면 데이터 저장도 연속적이고,
malloc호출 횟수도n_rows + 1번에서 2번으로 줄어들었습니다.
이차원 배열 정도라면 충분히 쓸 만은 하죠.그렇다면 혹시... 이차원 배열 인터페이스를 쓰면서도
malloc호출 횟수를 한 번으로 줄이는 방법은 없을까요?포인터 크기까지 포함해서 한 번에 할당하기
방법은 간단합니다. 방금 전까지는 데이터와 포인터 메모리를 따로 할당했었습니다.
이번에는 데이터와 포인터를 한 번에 할당하는 방법입니다.그림으로 나타내면 이렇습니다.

코드로는 대략 아래와 같습니다.
(이해를 위해 코드를 일부러 잘게 쪼개 놓았습니다.)단 이 방법을 추천하지는 않습니다.
포인터와 데이터 크기에 따라 메모리 정렬(Memory Alignment) 문제가 발생할 수 있기 때문입니다.메모리 정렬은 나중에 기회가 되면 다뤄 보도록 하겠습니다.
정렬 문제가 발생하는 이유와 자세한 해결 방법은 아래 링크를 참고해 주세요.
Dynamically Allocating 2D Arrays Efficiently (and Correctly!) in CVLA(Variable Length Array) 사용하기
C99부터 지원하는 가변 길이 배열 문법을 사용하는 방식입니다.
변수를 이용해서 배열 크기를 지정할 수 있습니다.
메모리를 해제할 필요도 없습니다. 간편하게 스택 내에서 메모리를 할당하기 때문입니다.단점은 컴파일 시간에 크기를 알 수 없기 때문에 구조체 멤버로 사용할 수 없다는 점입니다.
지뢰 찾기 프로그램은 게임판 크기와 함께 지뢰의 개수도 구조체에 같이 묶어서 저장해야 할 텐데요.
이런 경우는 VLA 사용이 어렵습니다.또, 호환성이 좋지 않아 모든 컴파일러에서 지원하지 않을 수도 있습니다.
더불어 데이터를 스택에 저장한다는 점은 나름 장점이지만, 데이터가 클 경우 스택 오버플로우가 발생할 수도 있습니다.여러모로 추천하지 않는 방법이지만, 간단한 프로그램이나 특정 환경에서는 사용할 만합니다.
Legitimate Use of Variable Length Arrays 라는 글에서 VLA가 문제가 되는 이유,
스택 오버플로우를 방지하면서도 VLA로 다차원 데이터를 할당하는 방법 등을 소개하고 있으니 참고 바랍니다.C언어 개발자는 어떤 방법을 쓸까?
C언어에서 다차원 데이터를 할당하는 여러 방법을 살펴보았습니다.
각자 장단점이 있는 거 같은데, 어떤 방법을 써야 할까요?언제 어떤 방법을 써야 하는지 명확한 가이드라인을 제시해 주는 자료가 많이 부족했습니다.
C언어 특성상 처음 프로그래밍을 배우는 사람이나 이미 C언어를 잘 아는 전문가를 위한 자료는 많아 보이는데, 이런 내용을 알려주는 자료는 정말 드물더라고요.어떤 게 국룰이다! 라고 누군가가 알려주면 참 좋을 텐데요.
그래서 C언어 전문가들이 어떤 방법을 쓰는지 알아보기 위해 오픈 소스 프로젝트의 코드를 조금 살펴보았습니다.
C언어로 되어 있으면서, 다차원 데이터를 다루는 프로젝트가 어떤 게 있을까요?
가장 먼저 파이썬의 수학 연산 라이브러리인 Numpy가 떠올랐습니다.
파이썬 리스트 자료형의 성능 한계를 극복하기 위해 C와 포트란으로 구현한 자료형을 쓴다고 들은 기억이 있었거든요.그래서 Numpy내 연산의 기본이 되는
ndarray타입을 살펴보았습니다.
ndarraytypes.h를 보면 1차원으로 풀어 쓰는 방식을 주로 사용하는 걸 볼 수 있습니다.data[i][j][k]는data[i*strides[0] + j*strides[1] + k*strides[2]]와 같이 접근하는 방식이죠.단, Multiarraymodule.c를 보면 1~3차원 데이터에 한해서
arr[i][j][k]와 같은 배열 인터페이스를 제공하는 함수도 찾을 수 있었습니다.그 외 다른 유명 오픈소스 프로젝트도 살펴보았습니다.
유명한 영상 인코딩 라이브러리 FFMPEG 역시 프레임 데이터를 1차원으로 저장하고 있었습니다.
터미널에서 즐기는 로그라이크 게임 Nethack은 지도와 같은 데이터를 1차원으로 풀어 저장하거나, 정적인 배열을 사용하는 걸 확인할 수 있었고요.
리눅스 커널 디스플레이 드라이버 DRM 관련 코드에서도 1차원 프레임 버퍼를 사용하고 있었습니다.행별로 메모리를 할당하거나, VLA를 사용하는 코드는 찾아보기 힘들었습니다.
(찾으면 알려주세요!)결론
종합해 보면 다차원 데이터를 할당할 때 1차원으로 데이터를 할당하고, 인덱스 계산을 통해 접근하는 방법을 가장 먼저 고려하는 게 좋겠습니다.
3차원 이상 데이터도 쉽게 구현이 가능하며, 각종 오버헤드가 적어 성능이 우수하고, 메모리 정렬이나 스택 오버플로우 문제도 없기 때문이죠.인터페이스가 익숙하지 않아서 불편하지만, 보다 보면 적응이 되는 부분도 있겠습니다.
2차원 데이터라면 포인터 연결을 통해 이차원 배열 인터페이스를 사용하는 것도 고려할 수 있겠고요.간단한 환경이라면 때에 따라 VLA를 고려할 수도 있겠습니다. 단순 테스트용이나, 스택 오버플로우가 발생하지 않을 정도의 작은 데이터에 사용해 볼 수 있겠네요.
설명을 위해 잠깐 무시하고 있었지만, 지뢰 찾기 프로그램은 비상식적으로 큰 게임판을 굳이 지원할 필요가 없습니다.
사용자가 만들 수 있는 게임판의 최대 크기를 정해놓고, 정적인 2차원 배열을 사용할 수도 있겠죠.
물론 데이터가 인접하게 저장되지는 않지만, 성능이 그리 중요하지 않다면 행별로 메모리를 할당하는 방법보다 구현이 훨씬 간편합니다.C언어뿐 아니라 다른 언어를 사용할 때도 염두에 두고 적용해 볼 수 있습니다.
예를 들어 파이썬에서 이차원 데이터를 다룬다고 할 때, 중첩된 리스트의 메모리 할당 매커니즘은 글에서 처음 구현한 행별 메모리 할당 방식과 가장 유사할 것입니다.
성능이 아쉽다면 이를 일차원으로 풀어서 저장해보고 성능을 비교해 볼 수 있겠죠.
혹은 이미 그렇게 하고 있는 Numpy 모듈을 사용하는 것도 좋은 방안이 될 테고요.다차원 데이터의 메모리 할당에 관해 공부하며 알아본 내용을 열심히 정리해 보았는데요.
아직 배움이 부족해 잘 모르고 넘어가거나 잘못 설명한 개념이 있을 수도 있습니다.
잘못된 내용이 있다면 지적해 주시기를 바랍니다.도움이 되었길 바랍니다. 감사합니다.