-
Python set의 순서는 어떻게 정해질까? CPython 구현으로 알아보는 해시 테이블 동작 원리Programming/TIL 2025. 2. 2. 22:10
파이썬 set 자료형의 순서 결정 원리를 CPython 소스코드 분석을 통해 파헤칩니다. 해시 테이블 구현 방식, 충돌 해결 전략, 초기화 방식에 따른 순서 차이까지 상세히 설명합니다. set.pop() 메서드의 기묘한 동작을 통해 집합 자료형의 내부 동작 원리와 구현 방식에 대해 분석합니다.
개요
Python의 set, 집합 자료형은 순서가 없는 자료형으로 알려져 있습니다.
하지만 데이터가 메모리에 저장되는 한, 어떤 방식으로든 순서가 있기 마련입니다.
파이썬에서
for문을 사용해 집합을 순회할 수 있는(iterable) 것도 순서가 있으니까 가능한 일이겠죠.
이런 식으로요.s = {"하나", "둘", "set", "집합"} for item in s: print(item)실행 시마다 출력되는 순서가 다르게 나올 수는 있지만, 어찌 되었든 순서가 있는 건 명확하죠.
오늘은 이 set 자료형 속 원소들의 순서가 어떻게 결정되는지 알아보겠습니다.
글은 Python 표준 구현체인 CPython, 3.12 버전을 기준으로 합니다.
set의 내부, C언어 소스코드를 살펴보고 동작 원리를 확인해 가며 순서가 어떻게 결정되는지 알아보겠습니다.C언어 코드는 최대한 이해하기 쉽게 단순화한 코드를 사용할 예정입니다.
원본 소스코드의 링크를 걸어두었기에 궁금하신 분은 원본 소스코드를 참고하시면 됩니다.CPython 집합 자료형은 해시 테이블을 이용해 데이터를 저장합니다.
해시 테이블 자료구조가 낯설더라도 이해할 수 있도록 간단한 설명을 달아두었는데요.
설명이 빈약하기에 다른 블로그 글들을 참고하셔도 좋겠습니다.글들:
- 해시 자료구조와 Java HashMap이 해시 충돌을 해결하는 방법
- CS - 해시테이블, 해시함수 정리(Chaining, Open addressing)
- Python으로 해시 테이블 구현하기
왜 이런 걸 알아보나요?
어느날 파이썬 공식 문서에서 기본 자료형 파트를 둘러보고 있었습니다.
set의 메서드 목록을 살펴보는데, 눈에 밟히는 녀석이 하나 있었습니다.
바로pop()메서드인데요.pop()자체는 흔한 메서드이지만, set에도pop()이 있다는 게 조금 의외였습니다.리스트 자료형의
pop()은 리스트의 마지막 요소를 뽑아내는 메서드인데...순서가 없는 집합 자료형에서
pop()을 할 수 있을까요?pop()을 하면 도대체 어떤 요소가 뽑혀 나올까요?공식 문서의 설명을 한번 살펴보았습니다.
Remove and return an arbitrary element from the set. Raises KeyError if the set is empty.
집합에서 임의의 원소를 선택해서 삭제 후 반환한다고 합니다.
"임의의 원소"란 말이죠...
한가지 아이디어가 떠올랐습니다.set을 이용한 랜덤 추첨 프로그램???
pop()이 임의의 원소를 선택한다면...
set을 이용해서 랜덤 추첨 프로그램을 만들 수도 있지 않을까요?귀찮게
import random을 하지 않아도 되니 나름 편리할 것 같습니다.간단한 코드를 작성하고 돌려보겠습니다.
result_set = {1, 2, 3, "꽝"} print(result_set.pop())1~3점 혹은 "꽝"이 나오는 간단한 추첨 프로그램입니다.
실행해 보니 첫 번째 결과로는1이, 두 번째 결과로는"꽝"이 나왔습니다.매 실행마다 결과가 다르게 나옵니다!
임의의 원소라는 말이 이런 뜻이었군요.
근데... 뭔가 이상합니다.
생각보다1이 많이 나오는 것 같습니다.
결과 분포가 뭔가 이상합니다. 수상해요.
100번 돌려본다면 어떨까요?
결과는 바 그래프로 나오게끔 코드를 짜두었습니다.
특이한 결과가 나왔습니다.
1혼자 100번 중 77번이나 나왔습니다2는 100중에 한 번도 나오지 않았구요...?3은 5번???? 나왔습니다
1000 번 돌리면 좀 다를까요?

별반 다르지 않습니다.
도대체 이 기묘한 분포의 원인은 무엇일까요?
- 왜
1이 많이 나오는 걸까요? - 왜
2는 한 번도 나오지 않는 걸까요? - 왜
2는 한 번도 안나오는 데,3번은 가뭄에 콩 나듯 가끔씩 나오는 걸까요?
너무 궁금해서 파이썬의 set 자료형이 어떻게 동작하는지, 특히 순서가 어떻게 결정 되는지를 파해쳐보기로 했습니다.
Python의 해시(hash)
공식 문서의 설명을 보면 set은 해시 가능한(hashable) 객체만 담을 수 있다고 합니다.
해시 가능한 객체란
__hash__()메서드를 구현한 객체를 뜻하는데요.정수나 문자열과 같은 내장 불변 객체는 기본적으로
__hash__()메서드가 구현되어 있습니다.한 번 확인해 볼까요?
results = [1, 2, 3, "꽝"] for item in results: print(f"Hash of {item}: {item.__hash__()}")첫 번째 실행 결과:
Hash of 1: 1 Hash of 2: 2 Hash of 3: 3 Hash of 꽝: 9048759147891022119두 번째 실행 결과:
Hash of 1: 1 Hash of 2: 2 Hash of 3: 3 Hash of 꽝: -4905176660018551155여러 번 실행 결과 다음을 발견할 수 있었습니다.
- 정수 자료형(
1,2,3)은 자신의 값을 해시로 사용합니다. - 문자열(
"꽝")은 실행할 때마다 해시값이 매번 달라집니다.
소스 코드를 살펴본 결과:
- 정수형은 값을 해시로
- 문자열은 시작시 랜덤하게 선택한 값을 이용해 해시값을 계산 함을 확인할 수 있었습니다.
왜 굳이 문자열의 해시값을 랜덤하게 만들까요?
해시 함수는 임의의 데이터를 고정된 길이의 해시값으로 변환하는 함수입니다.
input의 경우의 수(정의역)보다 output의 경우의 수(공역)가 작기 때문에 서로 다른 데이터가 같은 해시값을 가질 수도 있겠죠.
이를 해시 충돌이라고 하는데요.
해시를 이용한 데이터 구조는 해시 충돌 시 성능이 급격히 떨어질 수 있습니다.이를 악용하면 해시값이 같은 데이터만 잔뜩 넣어 프로그램 성능을 저하시키는 일이 가능합니다.
이런 DoS(Denial of Service) 공격을 방지하기 위해 해시값을 역 추적할 수 없도록 매 실행마다 다르게 나오도록 설계한 것이죠.한편
PYTHONHASHSEED환경 변수를 설정하면 여러 번 실행해도 같은 해시값을 얻을 수 있습니다.PYTHONHASHSEED=0 python hashswan.pyprint(hash("swan")) # -5160244623441228817우리의 추첨 프로그램을 다시 돌려보겠습니다.
print(f"HASHSEED: {os.environ.get('PYTHONHASHSEED')}") results = [1, 2, 3, "꽝"] for item in results: print(f"Hash of {item}: {item.__hash__()}") results_set = {1, 2, 3, "꽝"} print(f"Popped item: {results_set.pop()}")HASHSEED: 0 Hash of 1: 1 Hash of 2: 2 Hash of 3: 3 Hash of 꽝: 7727899227499050140 Popped item: 1HASHSEED: 90125 Hash of 1: 1 Hash of 2: 2 Hash of 3: 3 Hash of 꽝: -6316168958054087615 Popped item: 꽝이제
1이 많이 나오는 이유를 추정해 볼 수 있겠습니다.두 가지 가정을 세워보겠습니다.
- set에 저장되는 순서는 해시값에 의해 결정된다.
pop()은 순서가 가장 앞에 있는 원소를 뽑아낸다.
1, 2, 3과 같은 정수는 값이 그대로 해시값이 됩니다. 저장되는 순서도 이와 같겠죠.
한편 "꽝"이라는 문자열은 실행 시마다 해시값이 매번 달라집니다."꽝"이1보다 앞에 온다면pop()의 결과로"꽝"이, 아니라면1이 나올 것입니다.이러면
1이 많이 나오는 이유가 설명됩니다.그런데... 왜
3은 가끔씩 나오는 걸까요?3이 나오는데2는 한 번도 나오지 않는 이유는 무엇일까요???아직 이 의문이 풀리지 않았습니다.
이를 파헤쳐보기 위해 파이썬의 set 자료형을 더 깊게 살펴보겠습니다.
Python의 set 구현 살펴보기
파이썬의 set은 해시 테이블(Hash Table)을 이용해 데이터를 저장합니다.
먼저 해시 테이블에 대해 간단히 살펴보고 set의 내부 구현을 살펴보겠습니다.
해시 테이블(Hash Table)이란?
해시 테이블, 혹은 해시 맵은 해시값을 인덱스로 활용해 데이터를 저장하는 자료구조입니다.
문자열 "swan"의 해시값이 3이라면 테이블의 3번 인덱스(
table[3])에 "swan"을,
문자열 "duck"의 해시값이 5라면 테이블의 5번 인덱스(table[5])에 "duck"을 저장하는 식입니다.물론 앞서 언급했듯, 서로 다른 데이터의 해시값이 같은 경우가 있을 수 있습니다.
이런 해시 충돌을 해결하는 대표적인 방법이 두 가지가 있는데요.
체이닝(Chaining)과 개방 주소 방식(Open Addressing)입니다.체이닝은 같은 해시값을 가진 데이터를 연결 리스트로 연결하는 방식입니다.
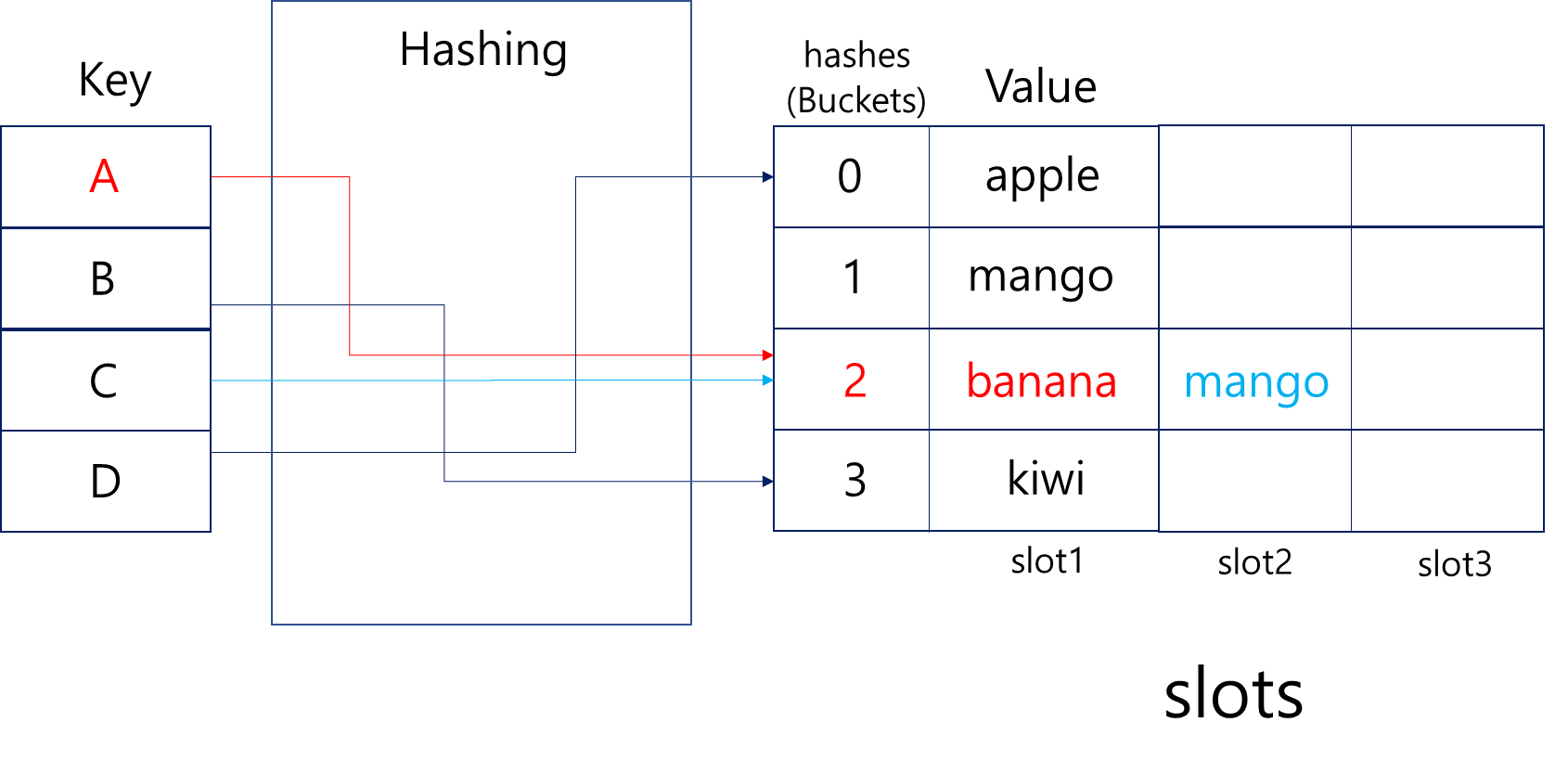
Java의 HashMap이 이런 체이닝 방식을 사용합니다.
선형 연결리스트를 사용하다 충돌이 많을 경우 트리구조(Red-Black Tree)로 변경해 성능을 높이도록 설계되어 있죠.한편 파이썬의 set은 개방 주소 방식을 사용하고 있습니다.
개방 주소 방식은 해시 충돌 시 다른 빈 공간을 찾아 데이터를 저장하는 방식입니다.
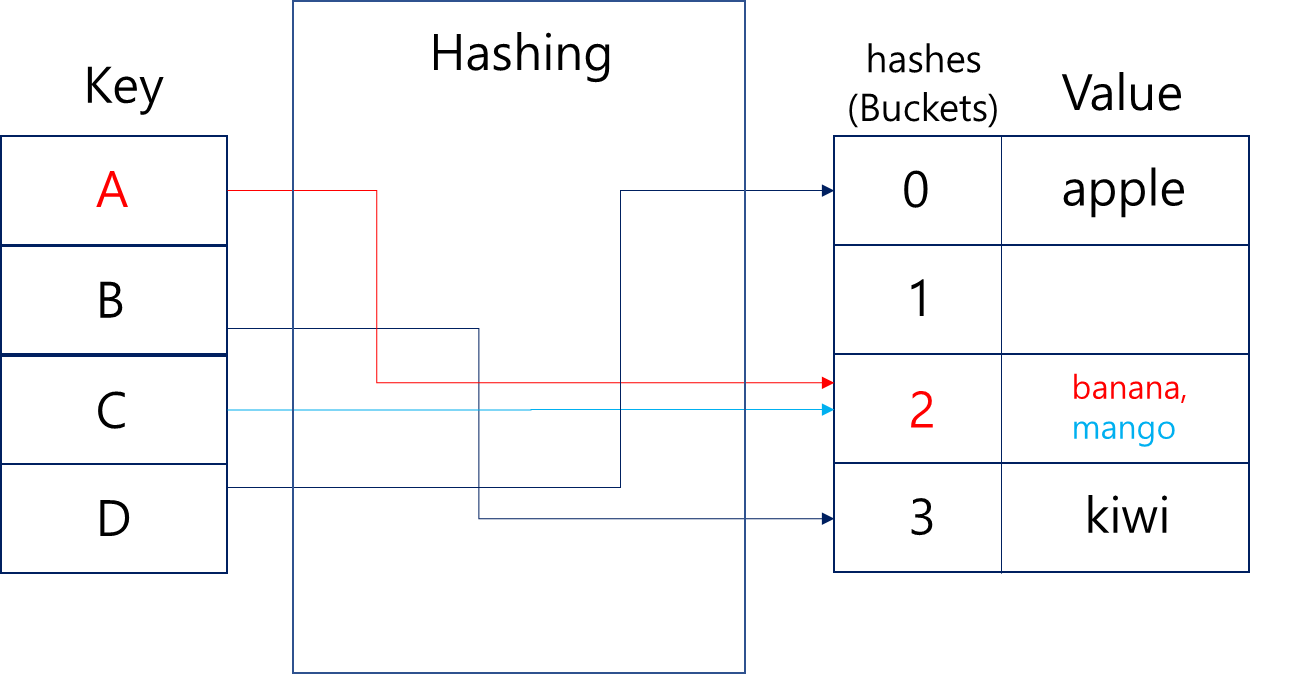
"mango"의 해시값이 2인데 이미 2번 인덱스에 "banana"가 저장되어 있습니다.
이런 경우 적절한 빈 공간인 4번 인덱스에 "mango"를 저장하는 식이죠.빈 공간을 찾는 전략에는 여러 방법이 있습니다.
이 빈 곳을 찾는 방식에 따라 해시 테이블 내 데이터 저장 순서가 달라질텐데요.
그러면 이제 파이썬의 set은 어떤 방법을 사용하는지, 구현 방식을 살펴보겠습니다.
CPython set 구현 살펴보기
set의 구현이 담겨있는 setobject.c를 살펴보겠습니다.
먼저 set의 해시테이블의 최소 크기는 8로 정의되어 있습니다.
#define PySet_MINSIZE 8데이터는
set_add_entry()함수를 통해 해시 테이블에 저장됩니다.먼저 데이터를 저장할 위치, 해시 테이블의 인덱스를 구해야 할 텐데요.
가장 처음에는 데이터의 해시값(
__hash__())을 테이블 크기로 나눈 나머지를 인덱스로 사용합니다.실제 구현 코드를 보면 나머지 연산 대신 비트 연산을 사용하고 있습니다.
내부적으로 해시 테이블의 크기를 항상 2의 제곱수로 유지하기 때문에 나머지 연산 대신 비트 연산으로 나머지를 구할 수 있습니다.2^n로 나눈 나머지는2^n - 1와&(bitwise AND) 연산으로 구할 수 있죠.이렇게 구한 인덱스에 데이터를 저장하는데, 이미 다른 데이터가 들어있는 경우에는 충돌이 발생합니다.
일단은 먼저 충돌이 발생하지 않은 경우, 첫 시도에 빈칸을 찾은 경우를 살펴보겠습니다.
mask = set_object->table_size - 1; i = hash & mask; while (1) { entry = &set_object->table[i]; // Empty slot if (entry->key == NULL) { goto found_unused; } // ... }빈 칸을 찾았으면 데이터를 저장합니다.
goto 문을 사용해 구현하고 있습니다.found_unused: set_object->fill++; set_object->used++; // Store data entry->key = key; entry->hash = hash; // No Resize Needed if (set_object->fill * 5 < mask * 3) { return 0; } else { return set_table_resize(set_object, set_object->used > 50000 ? set_object->used * 2 : set_object->used * 4); }저장 후 테이블의 사용률이 약 3/5를 넘어가면 테이블을 확장합니다.
테이블의 크기는 데이터가 적으면 4배, 데이터가 많으면 2배씩 확장합니다. 2의 제곱수를 유지하도록 설계되어 있습니다.
한편, 위치에 이미 다른 데이터가 들어있어 충돌이 발생한 경우 다음 위치를 찾아야 합니다.
코드는 간략하게 표현하면 이런 구조입니다.
#define LINEAR_PROBES 9 #define PERTURB_SHIFT 5 size_t perturb = hash; size_t i = hash & mask; size_t j; while (1) { entry = &table[i]; if (entry->key == NULL) goto found_unused; if (i + LINEAR_PROBES <= mask) { for (j = 0; j < LINEAR_PROBES; j++) { entry++; if (entry->key == NULL) goto found_unused; } } perturb >>= PERTURB_SHIFT; i = (i * 5 + 1 + perturb) & mask; }선형 탐색(Linear Probing)을 통해 다음 위치를 찾습니다.
다음 빈칸을 찾을 때까지 우측으로 이동하면서 빈칸을 탐색하는 방식입니다.모든 칸을 다 확인하면 비효율적이기 때문에 특정 횟수,
LINEAR_PROBES만큼만 이동하도록 합니다.LINEAR_PROBES는 9로 정의되어 있습니다.우측으로 빈칸 9개 이상이 없다면(
i + LINEAR_PROBES <= size - 1) 선형 탐색을 진행하지 않습니다.이후 선형 탐색에도 빈칸을 찾지 못했다면 특정 위치, 특수한 위치로 이동하여 다시 탐색을 시작합니다.
이동 위치는 다음과 같이 계산됩니다.
perturb >>= PERTURB_SHIFT; i = (i * 5 + 1 + perturb) & mask;왜 이런 계산을 하는지는 dictobject.c에 주석으로 상세히 적혀있습니다.
연속한 숫자가 서로 멀리 저장되도록, 해시값의 모든 비트를 사용해서 최대한 균등한 분포를 이루도록 고안한 산식이라고 합니다.요런 방식이구나~ 정도로만 이해하고 넘어가도록 하겠습니다.
set을 순회하는 순서는 해시 테이블에 저장된 순서대로 순회합니다.
0번 인덱스부터 마지막 인덱스까지 순회하며 데이터를 꺼내오죠.pop()메서드의 구현 코드는 해시 테이블을 순서대로 탐색하며 첫 번째로 만나는 데이터를 반환하고 삭제합니다.정확히는 이전에
pop()을 한 위치부터 순회하며 데이터를 찾는 방식입니다.
우리의 추첨 프로그램은pop()을 한 번만 호출하기 때문에 해시 테이블에서 가장 앞에 있는 데이터가 뽑혀 나오게 됩니다.이제 동작 원리를 이해했으니, 파이썬 코드로 set과 같은 자료 구조를 구현해 볼 수 있지 않을까요?
직접 구현한 set과 비교해보기
CPython의 set 구현을 참고해 set처럼 동작할 수 있는 클래스,
MY_SET을 만들어 보겠습니다.구현은 정말 최소한만 하고자 합니다.
그래서 테이블 사이즈를 키우는 리사이징 로직을 생략하겠습니다.set 내부 해시 테이블의 기본 사이즈는 8이고, 원소가 3/5 이상(5개) 차면 테이블을 확장하도록 설계되어 있습니다.
즉 리사이징 로직을 구현하지 않아도 원소 4개까지는 동작이 동일합니다.
class MY_SET: TABLE_SIZE = 8 MAX_ELEMENTS = 4 def __init__(self): self.table = [None] * self.TABLE_SIZE self.mask = self.TABLE_SIZE - 1 self.num_elements = 0add()메서드를 구현할 차례인데요.
역시 테이블의 크기가 8을 넘지 않음을 가정하고 구현하겠습니다.기존 C언어 구현에서 선형 탐색을 했던 걸 기억하시나요?
LINEAR_PROBES, 9칸만큼 우측으로 이동하며 빈칸을 찾는 방식이었는데요.우측에 남는 공간이 9칸보다 적다면 선형 탐색을 하지 않도록 설계가 되어 있었습니다.
우리의 미니멀 set 구현체는 테이블 크기가 8을 넘지 않을 예정이므로 선형 탐색도 생략하겠습니다.
PERTURB_SHIFT = 5 def add(self, key): if self.num_elements >= self.MAX_ELEMENTS: print("Set is full") return hash = key.__hash__() i = hash & self.mask perturb = hash while True: entry = self.table[i] if entry is None: self.table[idx] = key self.num_elements += 1 return # No linear probing perturb >>= PERTURB_SHIFT i = (i * 5 + 1 + perturb) & self.maskpop()메서드 구현도 생략하고, 대신 순서 확인을 위해 전체 해시 테이블을 출력하는__repr__()메서드만 구현하겠습니다.def __repr__(self): return str(self.table)이렇게 만든
MY_SET클래스와 파이썬의 set를 비교해 보겠습니다.비교용 코드를 작성하고
print(f"HASHSEED: {os.environ.get('PYTHONHASHSEED')}") print("-" * 50) ELEMENTS = [1, 2, 3, "꽝"] result_set = {1, 2, 3, "꽝"} result_myset = MY_SET() for element in ELEMENTS: result_myset.add(element) print(f"Python set: {result_set}") print(f"My set: {result_myset}")여러 시드로 실행해 봅니다.
HASHSEED: 0 -------------------------------------------------- Python set: {1, 2, 3, '꽝'} My set: [None, 1, 2, 3, '꽝', None, None, None]HASHSEED: 666 -------------------------------------------------- Python set: {'꽝', 1, 2, 3} My set: ['꽝', 1, 2, 3, None, None, None, None]대부분 순서가 같게 나오는 것을 확인할 수 있었는데요.
다르게 나오는 경우도 있었습니다.
HASHSEED: 90125 -------------------------------------------------- Python set: {'꽝', 2, 3, 1} My set: ['꽝', 1, 2, 3, None, None, None, None]HASHSEED: 999 -------------------------------------------------- Python set: {3, 1, 2, '꽝'} My set: ['꽝', 1, 2, 3, None, None, None, None]문제의
3이 앞에 나오는 경우도 보이네요.지금까지 살펴본 동작 원리만으로는
3이 앞에 나오는 이유를 설명할 수 없습니다.3이 앞에 오려면1이 저장된 위치보다 먼저, 즉 해시 테이블의 0번 인덱스에 저장되어야 합니다.
한편3의 해시값은 3이고,3을 8로 나눈 나머지도 3입니다."꽝"의 해시 테이블 인덱스가 3이고,"꽝"이 먼저 3번 인덱스에 저장되어 해시 충돌이 났다면,3이 다른 위치에 저장될 수는 있겠습니다.하지만
3을 먼저 저장했기 때문에3이 우선적으로 3번 인덱스에 저장되어야 합니다.그렇다면... 혹시
3보다"꽝"이 먼저 저장되는 걸까요?set의 초기화 방식에 따른 순서 차이
만약에... 파이썬 set을
{1, 2, 3, "꽝"}으로 초기화하는 대신, 빈 set에add()로 값을 추가한다면 결과가 다를까요?바로 실험해 보겠습니다.
print(f"HASHSEED: {os.environ.get('PYTHONHASHSEED')}") print("-" * 50) ELEMENTS = [1, 2, 3, "꽝"] result_set_initialized = {1, 2, 3, "꽝"} result_set_added = set() for element in ELEMENTS: result_set_added.add(element) result_myset = MY_SET() for element in ELEMENTS: result_myset.add(element) print(f"Python set(initialized): {result_set_initialized}") print(f"Python set(added): {result_set_added}") print(f"My set: {result_myset}")HASHSEED: 90125 -------------------------------------------------- Python set(initialized): {'꽝', 2, 3, 1} Python set(added): {'꽝', 1, 2, 3} My set: ['꽝', 1, 2, 3, None, None, None, None]HASHSEED: 999 -------------------------------------------------- Python set(initialized): {3, 1, 2, '꽝'} Python set(added): {'꽝', 1, 2, 3} My set: ['꽝', 1, 2, 3, None, None, None, None]예상이 맞았습니다!
원소를 하나씩 순서대로 넣는 방식과
{}초기화 방식의 결과가 다르게 나왔습니다.
초기화 방식이 해시테이블의 순서에 영향을 미치는 것이죠.왜 차이가 발생할까?
왜 초기화했을 때와
add()로 추가했을 때 결과가 다르게 나오는 걸까요?내부 코드를 아무리 봐도 이유를 알 수 없었습니다.
찾아보던 와중 Python dis 모듈에 대해 알게 되어서 한번 사용해보겠습니다.
파이썬 코드를 CPython 바이트 코드로 변환해 분석할 수 있게 해주는 모듈입니다.
사용은 간단합니다.
dis.dis()함수에 분석할 함수를 넣어주면 됩니다.import dis def set_initialize(): res_set = {1, 2, 3, "꽝"} dis.dis(set_initialize)분석 결과
4 2 BUILD_SET 0 4 LOAD_CONST 1 (frozenset({1, 2, 3, '꽝'})) 6 SET_UPDATE 1 8 STORE_FAST 0 (res_set) 10 RETURN_CONST 0 (None)BUILD_SET은 빈 set을 만드는 명령어입니다.SET_UPDATE는 인자로 받은 오브젝트를 가지고 set을 업데이트합니다.여기서 "인자로 받은 오브젝트"란
LOAD_CONST로 로드한frozenset({1, 2, 3, '꽝'})를 말합니다.즉 빈
res_set에frozenset({1, 2, 3, '꽝'})를 업데이트하는 것이죠.내부적으로
{1, 2, 3, '꽝'}은 불변 집합인frozenset으로 처리하는 모양입니다.이때
set_update_internal함수와set_merge_lock_held함수 함수를 거치게 되는데요.res_set에frozenset({1, 2, 3, '꽝'})에 담긴 원소를 순서대로 넣는 것과 같은 방식으로 동작합니다.즉
res_set에 원소를 넣는 순서는{1, 2 ,3, "꽝"} 순서가 아니라, frozenset 해시 테이블에 저장된 순서대로 들어가게 됩니다.이제 다시 시드 999의 순서 출력을 봐 볼까요?
HASHSEED: 999 -------------------------------------------------- Python set(initialized): {3, 1, 2, '꽝'} Python set(added): {'꽝', 1, 2, 3} My set: ['꽝', 1, 2, 3, None, None, None, None]frozenset도 일반 set과 같은 방식을 사용합니다.
즉,frozenset({1, 2, 3, '꽝'})은My set이나result_set_added와 같은 순서로 저장되어 있습니다.{"꽝", 1, 2, 3}순서가 되겠네요.initialized 방식으로 set을 만들면 빈 set에
{"꽝", 1, 2, 3}순서로 원소를 저장합니다.따라서
"꽝"이3보다 먼저 넣어집니다.
결국 3번 인덱스에"꽝"이 먼저 저장되고, 3번 인덱스에"꽝"이 저장되어 있기 때문에3은 다른 위치에 저장됩니다.다른 위치, 새로운 위치는 앞선 로직에 따라 이렇게 계산되겠죠.
perturb >>= PERTURB_SHIFT i = (i * 5 + 1 + perturb) & self.mask초기
perturb값은3의 해시값인 3입니다.
이를PERTURB_SHIFT값인 5만큼 오른쪽으로 shift 연산해 주면, 결과적으로 0이 됩니다.i값은 hash값인 3입니다.따라서
i값은 다음과 같이 계산됩니다.i = (3 * 5 + 1 + 0) % 8i = 16 % 8i = 0즉,
3은 0번 인덱스에 저장됩니다.pop()으로 원소를 꺼낼 때3이 나온 이유입니다.드디어 원리를 알아냈습니다...!
그러면
2는 왜 한 번도 나오지 않았을까요?
같은 원리로2가 먼저 나올 수도 있지 않을까요?첫 frozenset을 만들 때
"꽝"의 인덱스가 2번이고, 충돌 시 저장될 위치로 계산 결과 0이 나왔다면 가능하지 않을까요?"꽝"이 2번 인덱스에 저장되어 있기 때문에
2는 다른 위치에 저장됩니다.위치를 한 번 계산해 볼까요?
i = (2 * 5 + 1 + 0) % 8i = 11 % 8i = 33번 인덱스에 2를 먼저 저장하게 되겠네요.
이러면
3이 3번 인덱스에 들어갈 수 없습니다. 새로운 위치를 찾아야겠죠.
결국 산식에 따라3은 0번 인덱스에 저장됩니다.시드: 112333의 결과가 이를 반영합니다.
HASHSEED: 112333 hash of "꽝":2 -------------------------------------------------- Python set(initialized): {3, 1, '꽝', 2} Python set(added): {'꽝', 1, 2, 3} My set: ['꽝', 1, 2, 3, None, None, None, None]모든 의문이 해결되었습니다.
마치며
이제 확률 추첨 프로그램의 결과가 왜 기묘하게 나왔는지 알게 되었습니다.
그 과정에서 CPython set의 해시 테이블 순서 결정 로직도 알게 되었고요.모든 의문이 해결되어 이제 발 뻗고 잘 수 있게 되었습니다.
set의 저장 순서를 아는 게 개발할 때 도움이 될지는...? 잘 모르겠습니다.
그래도 알아보며 배운 것들이 많아 재밌는 시간이었네요. :)
도움이 되었길 바랍니다.
감사합니다.